Cycles and modularity in the wild
(Updated 2013-06-15. See comments at the end of the post)
(Updated 2014-04-12. A follow up post that applies the same analysis to Roslyn)
(Updated 2015-01-23. A much clearer version of this analysis has been done by Evelina Gabasova. She knows what she is talking about, so I highly recommend you read her post first!)
This is a follow up post to two earlier posts on module organization and cyclic dependencies.
I thought it would be interesting to look at some real projects written in C# and F#, and see how they compare in modularity and number of cyclic dependencies.
The plan
My plan was to take ten or so projects written in C# and ten or so projects written in F#, and somehow compare them.
I didn't want to spend too much time on this, and so rather than trying to analyze the source files, I thought I would cheat a little and analyze the compiled assemblies, using the Mono.Cecil library.
This also meant that I could get the binaries directly, using NuGet.
The projects I picked were:
C# projects
- Mono.Cecil, which inspects programs and libraries in the ECMA CIL format.
- NUnit
- SignalR for real-time web functionality.
- NancyFx, a web framework
- YamlDotNet, for parsing and emitting YAML.
- SpecFlow, a BDD tool.
- Json.NET.
- Entity Framework.
- ELMAH, a logging framework for ASP.NET.
- NuGet itself.
- Moq, a mocking framework.
- NDepend, a code analysis tool.
- And, to show I'm being fair, a business application that I wrote in C#.
F# projects
Unfortunately, there is not yet a wide variety of F# projects to choose from. I picked the following:
- FSharp.Core, the core F# library.
- FSPowerPack.
- FsUnit, extensions for NUnit.
- Canopy, a wrapper around the Selenium test automation tool.
- FsSql, a nice little ADO.NET wrapper.
- WebSharper, the web framework.
- TickSpec, a BDD tool.
- FSharpx, an F# library.
- FParsec, a parser library.
- FsYaml, a YAML library built on FParsec.
- Storm, a tool for testing web services.
- Foq, a mocking framework.
- Another business application that I wrote, this time in F#.
I did choose SpecFlow and TickSpec as being directly comparable, and also Moq and and Foq.
But as you can see, most of the F# projects are not directly comparable to the C# ones. For example, there is no direct F# equivalent to Nancy, or Entity Framework.
Nevertheless, I was hoping that I might observe some sort of pattern by comparing the projects. And I was right. Read on for the results!
What metrics to use?
I wanted to examine two things: "modularity" and "cyclic dependencies".
First, what should be the unit of "modularity"?
From a coding point of view, we generally work with files (Smalltalk being a notable exception), and so it makes sense to think of the file as the unit of modularity. A file is used to group related items together, and if two chunks of code are in different files, they are somehow not as "related" as if they were in the same file.
In C#, the best practice is to have one class per file. So 20 files means 20 classes. Sometimes classes have nested classes, but with rare exceptions, the nested class is in the same file as the parent class. This means that we can ignore them and just use top-level classes as our unit of modularity, as a proxy for files.
In F#, the best practice is to have one module per file (or sometimes more). So 20 files means 20 modules. Behind the scenes, modules are turned into static classes, and any classes defined within the module are turned into nested classes. So again, this means that we can ignore nested classes and just use top-level classes as our unit of modularity.
The C# and F# compilers generate many "hidden" types, for things such as LINQ, lambdas, etc. In some cases, I wanted to exclude these, and only include "authored" types, which have been coded for explicitly. I also excluded the case classes generated by F# discriminated unions from being "authored" classes as well. That means that a union type with three cases will be counted as one authored type rather than four.
So my definition of a top-level type is: a type that is not nested and which is not compiler generated.
The metrics I chose for modularity were:
- The number of top-level types as defined above.
- The number of authored types as defined above.
- The number of all types. This number would include the compiler generated types as well. Comparing this number to the top-level types gives us some idea of how representative the top-level types are.
- The size of the project. Obviously, there will be more types in a larger project, so we need to make adjustments based on the size of the project. The size metric I picked was the number of instructions, rather than the physical size of the file. This eliminates issues with embedded resources, etc.
Dependencies
Once we have our units of modularity, we can look at dependencies between modules.
For this analysis, I only want to include dependencies between types in the same assembly. In other words, dependencies on system types such as String or List do not count as a dependency.
Let's say we have a top-level type A and another top-level type B. Then I say that a dependency exists from A to B if:
- Type
Aor any of its nested types inherits from (or implements) typeBor any of its nested types. - Type
Aor any of its nested types has a field, property or method that references typeBor any of its nested types as a parameter or return value. This includes private members as well -- after all, it is still a dependency. - Type
Aor any of its nested types has a method implementation that references typeBor any of its nested types.
This might not be a perfect definition. But it is good enough for my purposes.
In addition to all dependencies, I thought it might be useful to look at "public" or "published" dependencies. A public dependency from A to B exists if:
- Type
Aor any of its nested types inherits from (or implements) typeBor any of its nested types. - Type
Aor any of its nested types has a public field, property or method that references typeBor any of its nested types as a parameter or return value. - Finally, a public dependency is only counted if the source type itself is public.
The metrics I chose for dependencies were:
- The total number of dependencies. This is simply the sum of all dependencies of all types. Again, there will be more dependencies in a larger project, but we will also take the size of the project into account.
- The number of types that have more than X dependencies. This gives us an idea of how many types are "too" complex.
Cyclic dependencies
Given this definition of dependency, then, a cyclic dependency occurs when two different top-level types depend on each other.
Note what not included in this definition. If a nested type in a module depends on another nested type in the same module, then that is not a cyclic dependency.
If there is a cyclic dependency, then there is a set of modules that are all linked together. For example, if A depends on B, B depends on C, and then say, C depends on A, then A, B and C are linked together. In graph theory, this is called a strongly connected component.
The metrics I chose for cyclic dependencies were:
- The number of cycles. That is, the number of strongly connected components which had more than one module in them.
- The size of the largest component. This gives us an idea of how complex the dependencies are.
I analyzed cyclic dependencies for all dependencies and also for public dependencies only.
Doing the experiment
First, I downloaded each of the project binaries using NuGet. Then I wrote a little F# script that did the following steps for each assembly:
- Analyzed the assembly using Mono.Cecil and extracted all the types, including the nested types
- For each type, extracted the public and implementation references to other types, divided into internal (same assembly) and external (different assembly).
- Created a list of the "top level" types.
- Created a dependency list from each top level type to other top level types, based on the lower level dependencies.
This dependency list was then used to extract various statistics, shown below. I also rendered the dependency graphs to SVG format (using graphViz).
For cycle detection, I used the QuickGraph library to extract the strongly connected components, and then did some more processing and rendering.
If you want the gory details, here is a link to the script that I used, and here is the raw data.
It is important to recognize that this is not a proper statistical study, just a quick analysis. However the results are quite interesting, as we shall see.
Modularity
Let's look at the modularity first.
Here are the modularity-related results for the C# projects:
| Project | Code size | Top-level types | Authored types | All types | Code/Top | Code/Auth | Code/All | Auth/Top | All/Top |
|---|---|---|---|---|---|---|---|---|---|
| ef | 269521 | 514 | 565 | 876 | 524 | 477 | 308 | 1.1 | 1.7 |
| jsonDotNet | 148829 | 215 | 232 | 283 | 692 | 642 | 526 | 1.1 | 1.3 |
| nancy | 143445 | 339 | 366 | 560 | 423 | 392 | 256 | 1.1 | 1.7 |
| cecil | 101121 | 240 | 245 | 247 | 421 | 413 | 409 | 1.0 | 1.0 |
| nuget | 114856 | 216 | 237 | 381 | 532 | 485 | 301 | 1.1 | 1.8 |
| signalR | 65513 | 192 | 229 | 311 | 341 | 286 | 211 | 1.2 | 1.6 |
| nunit | 45023 | 173 | 195 | 197 | 260 | 231 | 229 | 1.1 | 1.1 |
| specFlow | 46065 | 242 | 287 | 331 | 190 | 161 | 139 | 1.2 | 1.4 |
| elmah | 43855 | 116 | 140 | 141 | 378 | 313 | 311 | 1.2 | 1.2 |
| yamlDotNet | 23499 | 70 | 73 | 73 | 336 | 322 | 322 | 1.0 | 1.0 |
| fparsecCS | 57474 | 41 | 92 | 93 | 1402 | 625 | 618 | 2.2 | 2.3 |
| moq | 133189 | 397 | 420 | 533 | 335 | 317 | 250 | 1.1 | 1.3 |
| ndepend | 478508 | 734 | 828 | 843 | 652 | 578 | 568 | 1.1 | 1.1 |
| ndependPlat | 151625 | 185 | 205 | 205 | 820 | 740 | 740 | 1.1 | 1.1 |
| personalCS | 422147 | 195 | 278 | 346 | 2165 | 1519 | 1220 | 1.4 | 1.8 |
| TOTAL | 2244670 | 3869 | 4392 | 5420 | 580 | 511 | 414 | 1.1 | 1.4 |
And here are the results for the F# projects:
| Project | Code size | Top-level types | Authored types | All types | Code/Top | Code/Auth | Code/All | Auth/Top | All/Top |
|---|---|---|---|---|---|---|---|---|---|
| fsxCore | 339596 | 173 | 328 | 2024 | 1963 | 1035 | 168 | 1.9 | 11.7 |
| fsCore | 226830 | 154 | 313 | 1186 | 1473 | 725 | 191 | 2.0 | 7.7 |
| fsPowerPack | 117581 | 93 | 150 | 410 | 1264 | 784 | 287 | 1.6 | 4.4 |
| storm | 73595 | 67 | 70 | 405 | 1098 | 1051 | 182 | 1.0 | 6.0 |
| fParsec | 67252 | 8 | 24 | 245 | 8407 | 2802 | 274 | 3.0 | 30.6 |
| websharper | 47391 | 52 | 128 | 285 | 911 | 370 | 166 | 2.5 | 5.5 |
| tickSpec | 30797 | 34 | 49 | 170 | 906 | 629 | 181 | 1.4 | 5.0 |
| websharperHtml | 14787 | 18 | 28 | 72 | 822 | 528 | 205 | 1.6 | 4.0 |
| canopy | 15105 | 6 | 16 | 103 | 2518 | 944 | 147 | 2.7 | 17.2 |
| fsYaml | 15191 | 7 | 11 | 160 | 2170 | 1381 | 95 | 1.6 | 22.9 |
| fsSql | 15434 | 13 | 18 | 162 | 1187 | 857 | 95 | 1.4 | 12.5 |
| fsUnit | 1848 | 2 | 3 | 7 | 924 | 616 | 264 | 1.5 | 3.5 |
| foq | 26957 | 35 | 48 | 103 | 770 | 562 | 262 | 1.4 | 2.9 |
| personalFS | 118893 | 30 | 146 | 655 | 3963 | 814 | 182 | 4.9 | 21.8 |
| TOTAL | 1111257 | 692 | 1332 | 5987 | 1606 | 834 | 186 | 1.9 | 8.7 |
The columns are:
- Code size is the number of CIL instructions from all methods, as reported by Cecil.
- Top-level types is the total number of top-level types in the assembly, using the definition above.
- Authored types is the total number of types in the assembly, including nested types, enums, and so on, but excluding compiler generated types.
- All types is the total number of types in the assembly, including compiler generated types.
I have extended these core metrics with some extra calculated columns:
- Code/Top is the number of CIL instructions per top level type / module. This is a measure of how much code is associated with each unit of modularity. Generally, more is better, because you don't want to have to deal with multiple files if you don't have too. On the other hand, there is a trade off. Too many lines of code in a file makes reading the code impossible. In both C# and F#, good practice is not to have more than 500-1000 lines of code per file, and with a few exceptions, that seems to be the case in the source code that I looked at.
- Code/Auth is the number of CIL instructions per authored type. This is a measure of how "big" each authored type is.
- Code/All is the number of CIL instructions per type. This is a measure of how "big" each type is.
- Auth/Top is the ratio of all authored types to the top-level-types. It is a rough measure of how many authored types are in each unit of modularity.
- All/Top is the ratio of all types to the top-level-types. It is a rough measure of how many types are in each unit of modularity.
Analysis
The first thing I noticed is that, with a few exceptions, the code size is bigger for the C# projects than for the F# projects. Partly that is because I picked bigger projects, of course. But even for a somewhat comparable project like SpecFlow vs. TickSpec, the SpecFlow code size is bigger. It may well be that SpecFlow does a lot more than TickSpec, of course, but it also may be a result of using more generic code in F#. There is not enough information to know either way right now -- it would be interesting to do a true side by side comparison.
Next, the number of top-level types. I said earlier that this should correspond to the number of files in a project. Does it?
I didn't get all the sources for all the projects to do a thorough check, but I did a couple of spot checks. For example, for Nancy, there are 339 top level classes, which implies that there should be about 339 files. In fact, there are actually 322 .cs files, so not a bad estimate.
On the other hand, for SpecFlow there are 242 top level types, but only 171 .cs files, so a bit of an overestimate there. And for Cecil, the same thing: 240 top level classes but only 128 .cs files.
For the FSharpX project, there are 173 top level classes, which implies there should be about 173 files. In fact, there are actually only 78 .fs files, so it is a serious over-estimate by a factor of more than 2. And if we look at Storm, there are 67 top level classes. In fact, there are actually only 35 .fs files, so again it is an over-estimate by a factor of 2.
So it looks like the number of top level classes is always an over-estimate of the number of files, but much more so for F# than for C#. It would be worth doing some more detailed analysis in this area.
Ratio of code size to number of top-level types
The "Code/Top" ratio is consistently bigger for F# code than for C# code. Overall, the average top-level type in C# is converted into 580 instructions. But for F# that number is 1606 instructions, about three times as many.
I expect that this is because F# code is more concise than C# code. I would guess that 500 lines of F# code in a single module would create many more CIL instructions than 500 lines of C# code in a class.
If we visually plot "Code size" vs. "Top-level types", we get this chart:
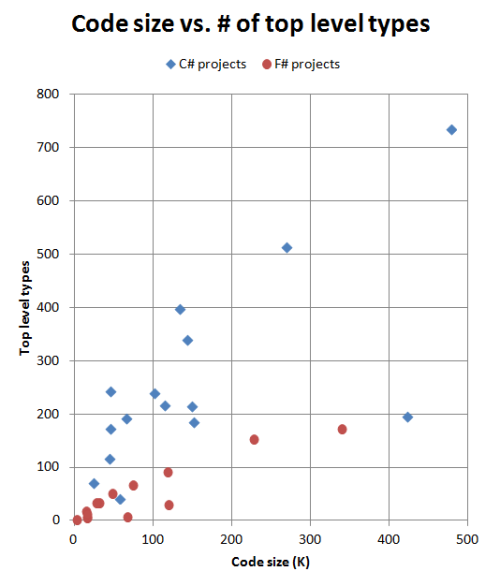
What's surprising to me is how distinct the F# and C# projects are in this chart. The C# projects seem to have a consistent ratio of about 1-2 top-level types per 1000 instructions, even across different project sizes. And the F# projects are consistent too, having a ratio of about 0.6 top-level types per 1000 instructions.
In fact, the number of top level types in F# projects seems to taper off as projects get larger, rather than increasing linearly like the C# projects.
The message I get from this chart is that, for a given size of project, an F# implementation will have fewer modules, and presumably less complexity as a result.
You probably noticed that there are two anomalies. Two C# projects are out of place -- the one at the 50K mark is FParsecCS and the one at the 425K mark is my business application.
I am fairly certain that this because both these implementations have some rather large C# classes in them, which helps the code ratio. Probably a necessarily evil for a parser, but in the case of my business application, I know that it is due to cruft accumulating over the years, and there are some massive classes that ought to be refactored into smaller ones. So a metric like this is probably a bad sign for a C# code base.
Ratio of code size to number of all types
On the other hand, if we compare the ratio of code to all types, including compiler generated ones, we get a very different result.
Here's the corresponding chart of "Code size" vs. "All types":

This is surprisingly linear for F#. The total number of types (including compiler generated ones) seems to depend closely on the size of the project. On the other hand, the number of types for C# seems to vary a lot.
The average "size" of a type is somewhat smaller for F# code than for C# code. The average type in C# is converted into about 400 instructions. But for F# that number is about 180 instructions.
I'm not sure why this is. Is it because the F# types are more fine-grained, or could it be because the F# compiler generates many more little types than the C# compiler? Without doing a more subtle analysis, I can't tell.
Ratio of top-level types to authored types
Having compared the type counts to the code size, let's now compare them to each other:
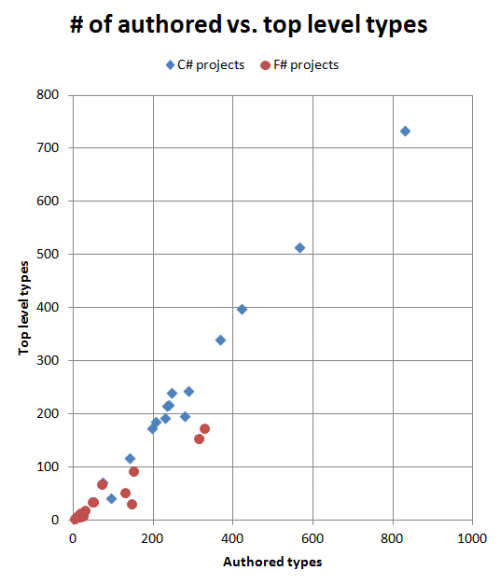
Again, there is a significant difference. For each unit of modularity in C# there are an average of 1.1 authored types. But in F# the average is 1.9, and for some projects a lot more than that.
Of course, creating nested types is trivial in F#, and quite uncommon in C#, so you could argue that this is not a fair comparison. But surely the ability to create a dozen types in as many lines of F# has some effect on the quality of the design? This is harder to do in C#, but there is nothing to stop you. So might this not mean that there is a temptation in C# to not be as fine-grained as you could potentially be?
The project with the highest ratio (4.9) is my F# business application. I believe that this is due to this being only F# project in this list which is designed around a specific business domain, I created many "little" types to model the domain accurately, using the concepts described here. For other projects created using DDD principles, I would expect to see this same high number.
Dependencies
Now let's look at the dependency relationships between the top level classes.
Here are the results for the C# projects:
| Project | Top Level Types | Total Dep. Count | Dep/Top | One or more dep. | Three or more dep. | Five or more dep. | Ten or more dep. | Diagram |
|---|---|---|---|---|---|---|---|---|
| ef | 514 | 2354 | 4.6 | 76% | 51% | 32% | 13% | svg dotfile |
| jsonDotNet | 215 | 913 | 4.2 | 69% | 42% | 30% | 14% | svg dotfile |
| nancy | 339 | 1132 | 3.3 | 78% | 41% | 22% | 6% | svg dotfile |
| cecil | 240 | 1145 | 4.8 | 73% | 43% | 23% | 13% | svg dotfile |
| nuget | 216 | 833 | 3.9 | 71% | 43% | 26% | 12% | svg dotfile |
| signalR | 192 | 641 | 3.3 | 66% | 34% | 19% | 10% | svg dotfile |
| nunit | 173 | 499 | 2.9 | 75% | 39% | 13% | 4% | svg dotfile |
| specFlow | 242 | 578 | 2.4 | 64% | 25% | 17% | 5% | svg dotfile |
| elmah | 116 | 300 | 2.6 | 72% | 28% | 22% | 6% | svg dotfile |
| yamlDotNet | 70 | 228 | 3.3 | 83% | 30% | 11% | 4% | svg dotfile |
| fparsecCS | 41 | 64 | 1.6 | 59% | 29% | 5% | 0% | svg dotfile |
| moq | 397 | 1100 | 2.8 | 63% | 29% | 17% | 7% | svg dotfile |
| ndepend | 734 | 2426 | 3.3 | 67% | 37% | 25% | 10% | svg dotfile |
| ndependPlat | 185 | 404 | 2.2 | 67% | 24% | 11% | 4% | svg dotfile |
| personalCS | 195 | 532 | 2.7 | 69% | 29% | 19% | 7% | |
| TOTAL | 3869 | 13149 | 3.4 | 70% | 37% | 22% | 9% |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
And here are the results for the F# projects:
| Project | Top Level Types | Total Dep. Count | Dep/Top | One or more dep. | Three or more dep. | Five or more dep. | Ten or more dep. | Diagram |
|---|---|---|---|---|---|---|---|---|
| fsxCore | 173 | 76 | 0.4 | 30% | 4% | 1% | 0% | svg dotfile |
| fsCore | 154 | 287 | 1.9 | 55% | 26% | 14% | 3% | svg dotfile |
| fsPowerPack | 93 | 68 | 0.7 | 38% | 13% | 2% | 0% | svg dotfile |
| storm | 67 | 195 | 2.9 | 72% | 40% | 18% | 4% | svg dotfile |
| fParsec | 8 | 9 | 1.1 | 63% | 25% | 0% | 0% | svg dotfile |
| websharper | 52 | 18 | 0.3 | 31% | 0% | 0% | 0% | svg dotfile |
| tickSpec | 34 | 48 | 1.4 | 50% | 15% | 9% | 3% | svg dotfile |
| websharperHtml | 18 | 37 | 2.1 | 78% | 39% | 6% | 0% | svg dotfile |
| canopy | 6 | 8 | 1.3 | 50% | 33% | 0% | 0% | svg dotfile |
| fsYaml | 7 | 10 | 1.4 | 71% | 14% | 0% | 0% | svg dotfile |
| fsSql | 13 | 14 | 1.1 | 54% | 8% | 8% | 0% | svg dotfile |
| fsUnit | 2 | 0 | 0.0 | 0% | 0% | 0% | 0% | svg dotfile |
| foq | 35 | 66 | 1.9 | 66% | 29% | 11% | 0% | svg dotfile |
| personalFS | 30 | 111 | 3.7 | 93% | 60% | 27% | 7% | |
| TOTAL | 692 | 947 | 1.4 | 49% | 19% | 8% | 1% |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The columns are:
- Top-level types is the total number of top-level types in the assembly, as before.
- Total dep. count is the total number of dependencies between top level types.
- Dep/Top is the number of dependencies per top level type / module only. This is a measure of how many dependencies the average top level type/module has.
- One or more dep is the number of top level types that have dependencies on one or more other top level types.
- Three or more dep. Similar to above, but with dependencies on three or more other top level types.
- Five or more dep. Similar to above.
- Ten or more dep. Similar to above. Top level types with this many dependencies will be harder to understand and maintain. So this is measure of how complex the project is.
The diagram column contains a link to a SVG file, generated from the dependencies, and also the DOT file that was used to generate the SVG. See below for a discussion of these diagrams. (Note that I can't expose the internals of my applications, so I will just give the metrics)
Analysis
These results are very interesting. For C#, the number of total dependencies increases with project size. Each top-level type depends on 3-4 others, on average.
On the other hand, the number of total dependencies in an F# project does not seem to vary too much with project size at all. Each F# module depends on no more than 1-2 others, on average. And the largest project (FSharpX) has a lower ratio than many of the smaller projects. My business app and the Storm project are the only exceptions.
Here's a chart of the relationship between code size and the number of dependencies:
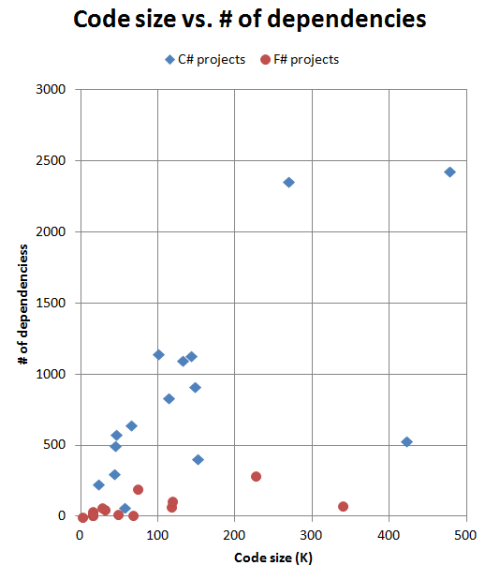
The disparity between C# and F# projects is very clear. The C# dependencies seem to grow linearly with project size, while the F# dependencies seem to be flat.
Distribution of dependencies
The average number of dependencies per top level type is interesting, but it doesn't help us understand the variability. Are there many modules with lots of dependencies? Or does each one just have a few?
This might make a difference in maintainability, perhaps. I would assume that a module with only one or two dependencies would be easier to understand in the context of the application that one with tens of dependencies.
Rather than doing a sophisticated statistical analysis, I thought I would keep it simple and just count how many top level types had one or more dependencies, three or more dependencies, and so on.
Here are the same results, displayed visually:
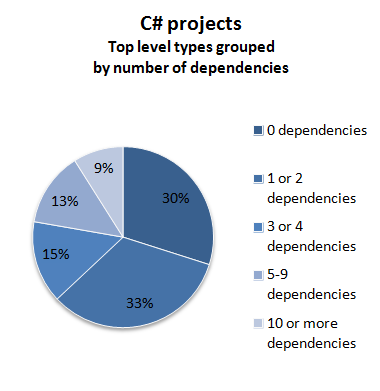
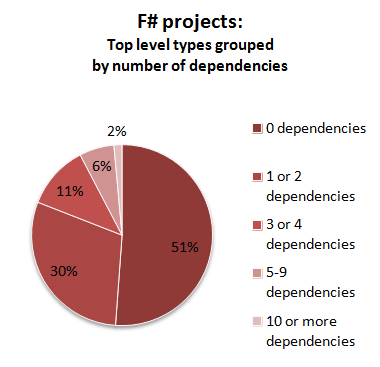
So, what can we deduce from these numbers?
First, in the F# projects, more than half of the modules have no outside dependencies at all. This is a bit surprising, but I think it is due to the heavy use of generics compared with C# projects.
Second, the modules in the F# projects consistently have fewer dependencies than the classes in the C# projects.
Finally, in the F# projects, modules with a high number of dependencies are quite rare -- less than 2% overall. But in the C# projects, 9% of classes have more than 10 dependencies on other classes.
The worst offender in the F# group is my very own F# application, which is even worse than my C# application with respect to these metrics. Again, it might be due to heavy use of non-generics in the form of domain-specific types, or it might just be that the code needs more refactoring!
The dependency diagrams
It might be useful to look at the dependency diagrams now. These are SVG files, so you should be able to view them in your browser.
Note that most of these diagrams are very big -- so after you open them you will need to zoom out quite a bit in order to see anything!
Let's start by comparing the diagrams for SpecFlow and TickSpec.
Here's the one for SpecFlow:

Here's the one for TickSpec:

Each diagram lists all the top-level types found in the project. If there is a dependency from one type to another, it is shown by an arrow. The dependencies point from left to right where possible, so any arrows going from right to left implies that there is a cyclic dependency.
The layout is done automatically by graphviz, but in general, the types are organized into columns or "ranks". For example, the SpecFlow diagram has 12 ranks, and the TickSpec diagram has five.
As you can see, there are generally a lot of tangled lines in a typical dependency diagram! How tangled the diagram looks is a sort of visual measure of the code complexity. For instance, if I was tasked to maintain the SpecFlow project, I wouldn't really feel comfortable until I had understood all the relationships between the classes. And the more complex the project, the longer it takes to come up to speed.
OO vs functional design revealed?
The TickSpec diagram is a lot simpler than the SpecFlow one. Is that because TickSpec perhaps doesn't do as much as SpecFlow?
The answer is no, I don't think that it has anything to do with the size of the feature set at all, but rather because the code is organized differently.
Looking at the SpecFlow classes (dotfile), we can see it follows good OOD and TDD practices by creating interfaces.
There's a TestRunnerManager and an ITestRunnerManager, for example.
And there are many other patterns that commonly crop up in OOD: "listener" classes and interfaces, "provider" classes and interfaces, "comparer" classes and interfaces, and so on.
But if we look at the TickSpec modules (dotfile) there are no interfaces at all. And no "listeners", "providers" or "comparers" either. There might well be a need for such things in the code, but either they are not exposed outside their module, or more likely, the role they play is fulfilled by functions rather than types.
I'm not picking on the SpecFlow code, by the way. It seems well designed, and is a very useful library, but I think it does highlight some of the differences between OO design and functional design.
Moq compared with Foq
Let's also compare the diagrams for Moq and Foq. These two projects do roughly the same thing, so the code should be comparable.
As before, the project written in F# has a much smaller dependency diagram.
Looking at the Moq classes (dotfile), we can see it includes the "Castle" library, which I didn't eliminate from the analysis. Out of the 249 classes with dependencies, only 66 are Moq specific. If we had considered only the classes in the Moq namespace, we might have had a cleaner diagram.
On the other hand, looking at the Foq modules (dotfile) there are only 23 modules with dependencies, fewer even than just the Moq classes alone.
So something is very different with code organization in F#.
FParsec compared with FParsecCS
The FParsec project is an interesting natural experiment. The project has two assemblies, roughly the same size, but one is written in C# and the other in F#.
It is a bit unfair to compare them directly, because the C# code is designed for parsing fast, while the F# code is more high level. But... I'm going to be unfair and compare them anyway!
Here are the diagrams for the F# assembly "FParsec" and C# assembly "FParsecCS".
They are both nice and clear. Lovely code!
What's not clear from the diagram is that my methodology is being unfair to the C# assembly.
For example, the C# diagram shows that there are dependencies between Operator, OperatorType, InfixOperator and so on.
But in fact, looking at the source code, these classes are all in the same physical file.
In F#, they would all be in the same module, and their relationships would not count as public dependencies. So the C# code is being penalized in a way.
Even so, looking at the source code, the C# code has 20 source files compared to F#'s 8, so there is still some difference in complexity.
What counts as a dependency?
In defence of my method though, the only thing that is keeping these FParsec C# classes together in the same file is good coding practice; it is not enforced by the C# compiler. Another maintainer could come along and unwittingly separate them into different files, which really would increase the complexity. In F# you could not do that so easily, and certainly not accidentally.
So it depends on what you mean by "module", and "dependency". In my view, a module contains things that really are "joined at the hip" and shouldn't easily be decoupled. Hence dependencies within a module don't count, while dependencies between modules do.
Another way to think about it is that F# encourages high coupling in some areas (modules) in exchange for low coupling in others. In C#, the only kind of strict coupling available is class-based. Anything looser, such as using namespaces, has to be enforced using good practices or a tool such as NDepend.
Whether the F# approach is better or worse depends on your preference. It does make certain kinds of refactoring harder as a result.
Cyclic dependencies
Finally, we can turn our attention to the oh-so-evil cyclic dependencies. (If you want to know why they are bad, read this post ).
Here are the cyclic dependency results for the C# projects.
| Project | Top-level types | Cycle count | Partic. | Partic.% | Max comp. size | Cycle count (public) | Partic. (public) | Partic.% (public) | Max comp. size (public) | Diagram |
|---|---|---|---|---|---|---|---|---|---|---|
| ef | 514 | 14 | 123 | 24% | 79 | 1 | 7 | 1% | 7 | svg dotfile |
| jsonDotNet | 215 | 3 | 88 | 41% | 83 | 1 | 11 | 5% | 11 | svg dotfile |
| nancy | 339 | 6 | 35 | 10% | 21 | 2 | 4 | 1% | 2 | svg dotfile |
| cecil | 240 | 2 | 125 | 52% | 123 | 1 | 50 | 21% | 50 | svg dotfile |
| nuget | 216 | 4 | 24 | 11% | 10 | 0 | 0 | 0% | 1 | svg dotfile |
| signalR | 192 | 3 | 14 | 7% | 7 | 1 | 5 | 3% | 5 | svg dotfile |
| nunit | 173 | 2 | 80 | 46% | 78 | 1 | 48 | 28% | 48 | svg dotfile |
| specFlow | 242 | 5 | 11 | 5% | 3 | 1 | 2 | 1% | 2 | svg dotfile |
| elmah | 116 | 2 | 9 | 8% | 5 | 1 | 2 | 2% | 2 | svg dotfile |
| yamlDotNet | 70 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | svg dotfile |
| fparsecCS | 41 | 3 | 6 | 15% | 2 | 1 | 2 | 5% | 2 | svg dotfile |
| moq | 397 | 9 | 50 | 13% | 15 | 0 | 0 | 0% | 1 | svg dotfile |
| ndepend | 734 | 12 | 79 | 11% | 22 | 8 | 36 | 5% | 7 | svg dotfile |
| ndependPlat | 185 | 2 | 5 | 3% | 3 | 0 | 0 | 0% | 1 | svg dotfile |
| personalCS | 195 | 11 | 34 | 17% | 8 | 5 | 19 | 10% | 7 | svg dotfile |
| TOTAL | 3869 | 683 | 18% | 186 | 5% | svg dotfile |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
And here are the results for the F# projects:
| Project | Top-level types | Cycle count | Partic. | Partic.% | Max comp. size | Cycle count (public) | Partic. (public) | Partic.% (public) | Max comp. size (public) | Diagram |
|---|---|---|---|---|---|---|---|---|---|---|
| fsxCore | 173 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fsCore | 154 | 2 | 5 | 3% | 3 | 0 | 0 | 0% | 1 | svg dotfile |
| fsPowerPack | 93 | 1 | 2 | 2% | 2 | 0 | 0 | 0% | 1 | svg dotfile |
| storm | 67 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fParsec | 8 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| websharper | 52 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 0 | . |
| tickSpec | 34 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| websharperHtml | 18 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| canopy | 6 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fsYaml | 7 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fsSql | 13 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| fsUnit | 2 | 0 | 0 | 0% | 0 | 0 | 0 | 0% | 0 | . |
| foq | 35 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| personalFS | 30 | 0 | 0 | 0% | 1 | 0 | 0 | 0% | 1 | . |
| TOTAL | 692 | 7 | 1% | 0 | 0% | . |
{kind=link}
{kind=link}
The columns are:
- Top-level types is the total number of top-level types in the assembly, as before.
- Cycle count is the number of cycles altogether. Ideally it would be zero. But larger is not necessarily worse. Better to have 10 small cycles than one giant one, I think.
- Partic.. The number of top level types that participate in any cycle.
- Partic.%. The number of top level types that participate in any cycle, as a percent of all types.
- Max comp. size is the number of top level types in the largest cyclic component. This is a measure of how complex the cycle is. If there are only two mutually dependent types, then the cycle is a lot less complex than, say, 123 mutually dependent types.
- ... (public) columns have the same definitions, but using only public dependencies. I thought it would be interesting to see what effect it would have to limit the analysis to public dependencies only.
- The diagram column contains a link to a SVG file, generated from the dependencies in the cycles only, and also the DOT file that was used to generate the SVG. See below for an analysis.
Analysis
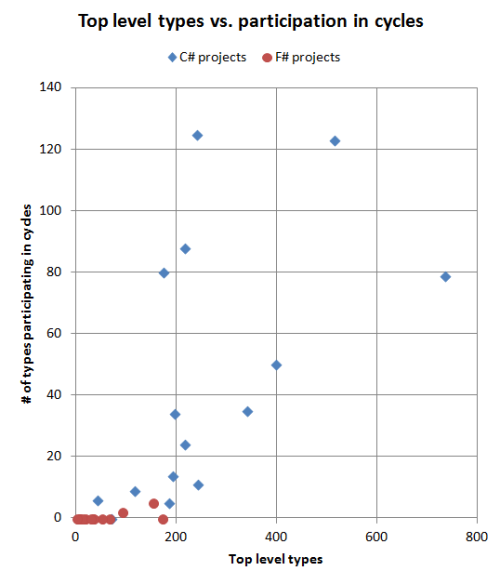
If we are looking for cycles in the F# code, we will be sorely disappointed. Only two of the F# projects have cycles at all, and those are tiny. For example in FSharp.Core there is a mutual dependency between two types right next to each other in the same file, here.
On the other hand, almost all the C# projects have one or more cycles. Entity Framework has the most cycles, involving 24% of the classes, and Cecil has the worst participation rate, with over half of the classes being involved in a cycle.
Even NDepend has cycles, although to be fair, there may be good reasons for this. First NDepend focuses on removing cycles between namespaces, not classes so much, and second, it's possible that the cycles are between types declared in the same source file. As a result, my method may penalize well-organized C# code somewhat (as noted in the FParsec vs. FParsecCS discussion above).
Why the difference between C# and F#?
- In C#, there is nothing stopping you from creating cycles -- a perfect example of accidental complexity. In fact, you have to make a special effort to avoid them.
- In F#, of course, it is the other way around. You can't easily create cycles at all.
My business applications compared
One more comparison. As part of my day job, I have written a number of business applications in C#, and more recently, in F#. Unlike the other projects listed here, they are very focused on addressing a particular business need, with lots of domain specific code, custom business rules, special cases, and so on.
Both projects were produced under deadline, with changing requirements and all the usual real world constraints that stop you writing ideal code. Like most developers in my position, I would love a chance to tidy them up and refactor them, but they do work, the business is happy, and I have to move on to new things.
Anyway, let's see how they stack up to each other. I can't reveal any details of the code other than the metrics, but I think that should be enough to be useful.
Taking the C# project first:
- It has 195 top level types, about 1 for every 2K of code. Comparing this with other C# projects, there should be many more top level types than this. And in fact, I know that this is true. As with many projects (this one is 6 years old) it is lower risk to just add a method to an existing class rather than refactoring it, especially under deadline. Keeping old code stable is always a higher priority than making it beautiful! The result is that classes grow too large over time.
- The flip side of having large classes is that there many fewer cross-class dependencies! It has some of the better scores among the C# projects. So it goes to show that dependencies aren't the only metric. There has to be a balance.
- In terms of cyclic dependencies, it's pretty typical for a C# project. There are a number of them (11) but the largest involves only 8 classes.
Now let's look at my F# project:
- It has 30 modules, about 1 for every 4K of code. Comparing this with other F# projects, it's not excessive, but perhaps a bit of refactoring is in order.
- As an aside, in my experience with maintaining this code, I have noticed that, unlike C# code, I don't feel that I have to add cruft to existing modules when feature requests come in. Instead, I find that in many cases, the faster and lower risk way of making changes is simply to create a new module and put all the code for a new feature in there. Because the modules have no state, a function can live anywhere -- it is not forced to live in the same class. Over time this approach may create its own problems too (COBOL anyone?) but right now, I find it a breath of fresh air.
- The metrics show that there are an unusually large number of "authored" types per module (4.9). As I noted above, I think this is a result of having fine-grained DDD-style design. The code per authored type is in line with the other F# projects, so that implies they are not too big or small.
- Also, as I noted earlier, the inter-module dependencies are the worst of any F# project. I know that there are some API/service functions that depend on almost all the other modules, but this
could be a clue that they might need refactoring.
- However, unlike C# code, I know exactly where to find these problem modules. I can be fairly certain that all these modules are in the top layer of my application and will thus appear at the bottom of the module list in Visual Studio. How can I be so sure? Because...
- In terms of cyclic dependencies, it's pretty typical for a F# project. There aren't any.
Summary
I started this analysis from curiosity -- was there any meaningful difference in the organization of C# and F# projects?
I was quite surprised that the distinction was so clear. Given these metrics, you could certainly predict which language the assembly was written in.
- Project complexity. For a given number of instructions, a C# project is likely to have many more top level types (and hence files) than an F# one -- more than double, it seems.
- Fine-grained types. For a given number of modules, a C# project is likely to have fewer authored types than an F# one, implying that the types are not as fine-grained as they could be.
- Dependencies. In a C# project, the number of dependencies between classes increases linearly with the size of the project. In an F# project, the number of dependencies is much smaller and stays relatively flat.
- Cycles. In a C# project, cycles occur easily unless care is taken to avoid them. In an F# project, cycles are extremely rare, and if present, are very small.
Perhaps this has do with the competency of the programmer, rather than a difference between languages? Well, first of all, I think that the quality of the C# projects is quite good on the whole -- I certainly wouldn't claim that I could write better code! And, in two cases in particular, the C# and F# projects were written by the same person, and differences were still apparent, so I don't think this argument holds up.
Future work
This approach of using just the binaries might have gone as far as it can go. For a more accurate analysis, we would need to use metrics from the source code as well (or maybe the pdb file).
For example, a high "instructions per type" metric is good if it corresponds to small source files (concise code), but not if it corresponds to large ones (bloated classes). Similarly, my definition of modularity used top-level types rather than source files, which penalized C# somewhat over F#.
So, I don't claim that this analysis is perfect (and I hope haven't made a terrible mistake in the analysis code!) but I think that it could be a useful starting point for further investigation.
Update 2013-06-15
This post caused quite a bit of interest. Based on feedback, I made the following changes:
Assemblies profiled
- Added Foq and Moq (at the request of Phil Trelford).
- Added the C# component of FParsec (at the request of Dave Thomas and others).
- Added two NDepend assemblies.
- Added two of my own projects, one C# and one F#.
As you can see, adding seven new data points (five C# and two F# projects) didn't change the overall analysis.
Algorithm changes
- Made definition of "authored" type stricter. Excluded types with "GeneratedCodeAttribute" and F# types that are subtypes of a sum type. This had an effect on the F# projects and reduced the "Auth/Top" ratio somewhat.
Text changes
- Rewrote some of the analysis.
- Removed the unfair comparison of YamlDotNet with FParsec.
- Added a comparison of the C# component and F# components of FParsec.
- Added a comparison of Moq and Foq.
- Added a comparison of my own two projects.
The orginal post is still available here