Using map, apply, bind and sequence in practice
This post is the fifth in a series.
In the first two posts, I described some of the core functions for dealing with generic data types: map, bind, and so on.
In the third post, I discussed "applicative" vs "monadic" style, and how to lift values and functions to be consistent with each other.
In the previous post, I introduced traverse and sequence as a way of working with lists of elevated values.
In this post, we'll finish up by working through a practical example that uses all the techniques that have been discussed so far.
Series contents
Here's a list of shortcuts to the various functions mentioned in this series:
- Part 1: Lifting to the elevated world
- Part 2: How to compose world-crossing functions
- Part 3: Using the core functions in practice
- Part 4: Mixing lists and elevated values
- Part 5: A real-world example that uses all the techniques
- Part 6: Designing your own elevated world
- Part 7: Summary
Part 5: A real-world example that uses all the techniques
Example: Downloading and processing a list of websites
The example will be a variant of the one mentioned at the beginning of the third post:
- Given a list of websites, create an action that finds the site with the largest home page.
Let's break this down into steps:
First we'll need to transform the urls into a list of actions, where each action downloads the page and gets the size of the content.
And then we need to find the largest content, but in order to do this we'll have to convert the list of actions into a single action containing a list of sizes.
And that's where traverse or sequence will come in.
Let's get started!
The downloader
First we need to create a downloader. I would use the built-in System.Net.WebClient class, but for some reason it doesn't allow override of the timeout.
I'm going to want to have a small timeout for the later tests on bad uris, so this is important.
One trick is to just subclass WebClient and intercept the method that builds a request. So here it is:
// define a millisecond Unit of Measure
type [<Measure>] ms
/// Custom implementation of WebClient with settable timeout
type WebClientWithTimeout(timeout:int<ms>) =
inherit System.Net.WebClient()
override this.GetWebRequest(address) =
let result = base.GetWebRequest(address)
result.Timeout <- int timeout
result
Notice that I'm using units of measure for the timeout value. I find that units of measure are invaluable to distiguish seconds from milliseconds. I once accidentally set a timeout to 2000 seconds rather than 2000 milliseconds and I don't want to make that mistake again!
The next bit of code defines our domain types. We want to be able to keep the url and the size together as we process them. We could use a tuple, but I am a proponent of using types to model your domain, if only for documentation.
// The content of a downloaded page
type UriContent =
UriContent of System.Uri * string
// The content size of a downloaded page
type UriContentSize =
UriContentSize of System.Uri * int
Yes, this might be overkill for a trivial example like this, but in a more serious project I think it is very much worth doing.
Now for the code that does the downloading:
/// Get the contents of the page at the given Uri
/// Uri -> Async<Result<UriContent>>
let getUriContent (uri:System.Uri) =
async {
use client = new WebClientWithTimeout(1000<ms>) // 1 sec timeout
try
printfn " [%s] Started ..." uri.Host
let! html = client.AsyncDownloadString(uri)
printfn " [%s] ... finished" uri.Host
let uriContent = UriContent (uri, html)
return (Result.Success uriContent)
with
| ex ->
printfn " [%s] ... exception" uri.Host
let err = sprintf "[%s] %A" uri.Host ex.Message
return Result.Failure [err ]
}
Notes:
- The .NET library will throw on various errors, so I am catching that and turning it into a
Failure. - The
use client =section ensures that the client will be correctly disposed at the end of the block. - The whole operation is wrapped in an
asyncworkflow, and thelet! html = client.AsyncDownloadStringis where the download happens asynchronously. - I've added some
printfns for tracing, just for this example. In real code, I wouldn't do this of course!
Before moving on, let's test this code interactively. First we need a helper to print the result:
let showContentResult result =
match result with
| Success (UriContent (uri, html)) ->
printfn "SUCCESS: [%s] First 100 chars: %s" uri.Host (html.Substring(0,100))
| Failure errs ->
printfn "FAILURE: %A" errs
And then we can try it out on a good site:
System.Uri ("http://google.com")
|> getUriContent
|> Async.RunSynchronously
|> showContentResult
// [google.com] Started ...
// [google.com] ... finished
// SUCCESS: [google.com] First 100 chars: <!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="en-GB"><head><meta cont
and a bad one:
System.Uri ("http://example.bad")
|> getUriContent
|> Async.RunSynchronously
|> showContentResult
// [example.bad] Started ...
// [example.bad] ... exception
// FAILURE: ["[example.bad] "The remote name could not be resolved: 'example.bad'""]
Extending the Async type with map and apply and bind
At this point, we know that we are going to be dealing with the world of Async, so before we go any further, let's make sure that we have our four core functions available:
module Async =
let map f xAsync = async {
// get the contents of xAsync
let! x = xAsync
// apply the function and lift the result
return f x
}
let retn x = async {
// lift x to an Async
return x
}
let apply fAsync xAsync = async {
// start the two asyncs in parallel
let! fChild = Async.StartChild fAsync
let! xChild = Async.StartChild xAsync
// wait for the results
let! f = fChild
let! x = xChild
// apply the function to the results
return f x
}
let bind f xAsync = async {
// get the contents of xAsync
let! x = xAsync
// apply the function but don't lift the result
// as f will return an Async
return! f x
}
These implementations are straightforward:
- I'm using the
asyncworkflow to work withAsyncvalues. - The
let!syntax inmapextracts the content from theAsync(meaning run it and await the result). - The
returnsyntax inmap,retn, andapplylifts the value to anAsyncusingreturn. - The
applyfunction runs the two parameters in parallel using a fork/join pattern. If I had instead writtenlet! fChild = ...followed by alet! xChild = ...that would have been monadic and sequential, which is not what I wanted. - The
return!syntax inbindmeans that the value is already lifted and not to callreturnon it.
Getting the size of the downloaded page
Getting back on track, we can continue from the downloading step and move on to the process of converting the result to a UriContentSize:
/// Make a UriContentSize from a UriContent
/// UriContent -> Result<UriContentSize>
let makeContentSize (UriContent (uri, html)) =
if System.String.IsNullOrEmpty(html) then
Result.Failure ["empty page"]
else
let uriContentSize = UriContentSize (uri, html.Length)
Result.Success uriContentSize
If the input html is null or empty we'll treat this an error, otherwise we'll return a UriContentSize.
Now we have two functions and we want to combine them into one "get UriContentSize given a Uri" function. The problem is that the outputs and inputs don't match:
getUriContentisUri -> Async<Result<UriContent>>makeContentSizeisUriContent -> Result<UriContentSize>
The answer is to transform makeContentSize from a function that takes a UriContent as input into
a function that takes a Async<Result<UriContent>> as input. How can we do that?
First, use Result.bind to convert it from an a -> Result<b> function to a Result<a> -> Result<b> function.
In this case, UriContent -> Result<UriContentSize> becomes Result<UriContent> -> Result<UriContentSize>.
Next, use Async.map to convert it from an a -> b function to a Async<a> -> Async<b> function.
In this case, Result<UriContent> -> Result<UriContentSize> becomes Async<Result<UriContent>> -> Async<Result<UriContentSize>>.

And now that it has the right kind of input, so we can compose it with getUriContent:
/// Get the size of the contents of the page at the given Uri
/// Uri -> Async<Result<UriContentSize>>
let getUriContentSize uri =
getUriContent uri
|> Async.map (Result.bind makeContentSize)
That's some gnarly type signature, and it's only going to get worse! It's at times like these that I really appreciate type inference.
Let's test again. First a helper to format the result:
let showContentSizeResult result =
match result with
| Success (UriContentSize (uri, len)) ->
printfn "SUCCESS: [%s] Content size is %i" uri.Host len
| Failure errs ->
printfn "FAILURE: %A" errs
And then we can try it out on a good site:
System.Uri ("http://google.com")
|> getUriContentSize
|> Async.RunSynchronously
|> showContentSizeResult
// [google.com] Started ...
// [google.com] ... finished
//SUCCESS: [google.com] Content size is 44293
and a bad one:
System.Uri ("http://example.bad")
|> getUriContentSize
|> Async.RunSynchronously
|> showContentSizeResult
// [example.bad] Started ...
// [example.bad] ... exception
//FAILURE: ["[example.bad] "The remote name could not be resolved: 'example.bad'""]
Getting the largest size from a list
The last step in the process is to find the largest page size.
That's easy. Once we have a list of UriContentSize, we can easily find the largest one using List.maxBy:
/// Get the largest UriContentSize from a list
/// UriContentSize list -> UriContentSize
let maxContentSize list =
// extract the len field from a UriContentSize
let contentSize (UriContentSize (_, len)) = len
// use maxBy to find the largest
list |> List.maxBy contentSize
Putting it all together
We're ready to assemble all the pieces now, using the following algorithm:
- Start with a list of urls
- Turn the list of strings into a list of uris (
Uri list) - Turn the list of
Uris into a list of actions (Async<Result<UriContentSize>> list) - Next we need to swap the top two parts of the stack. That is, transform a
List<Async>into aAsync<List>.
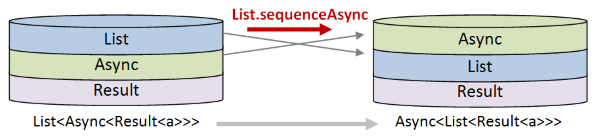
- Next we need to swap the bottom two parts of the stack -- transform a
List<Result>into aResult<List>. But the two bottom parts of the stack are wrapped in anAsyncso we need to useAsync.mapto do this.
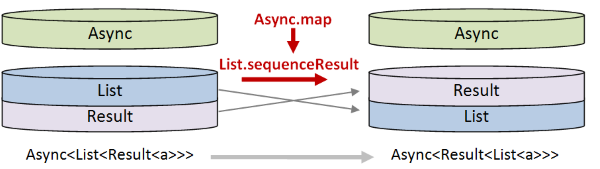
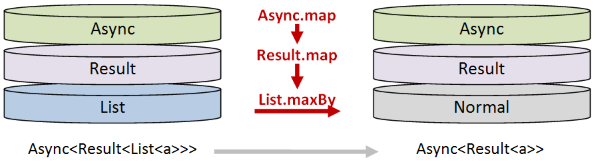
- Finally we need to use
List.maxByon the bottomListto convert it into a single value. That is, transform aList<UriContentSize>into aUriContentSize. But the bottom of the stack is wrapped in aResultwrapped in anAsyncso we need to useAsync.mapandResult.mapto do this.
Here's the complete code:
/// Get the largest page size from a list of websites
let largestPageSizeA urls =
urls
// turn the list of strings into a list of Uris
// (In F# v4, we can call System.Uri directly!)
|> List.map (fun s -> System.Uri(s))
// turn the list of Uris into a "Async<Result<UriContentSize>> list"
|> List.map getUriContentSize
// turn the "Async<Result<UriContentSize>> list"
// into an "Async<Result<UriContentSize> list>"
|> List.sequenceAsyncA
// turn the "Async<Result<UriContentSize> list>"
// into a "Async<Result<UriContentSize list>>"
|> Async.map List.sequenceResultA
// find the largest in the inner list to get
// a "Async<Result<UriContentSize>>"
|> Async.map (Result.map maxContentSize)
This function has signature string list -> Async<Result<UriContentSize>>, which is just what we wanted!
There are two sequence functions involved here: sequenceAsyncA and sequenceResultA. The implementations are as you would expect from
all the previous discussion, but I'll show the code anyway:
module List =
/// Map a Async producing function over a list to get a new Async
/// using applicative style
/// ('a -> Async<'b>) -> 'a list -> Async<'b list>
let rec traverseAsyncA f list =
// define the applicative functions
let (<*>) = Async.apply
let retn = Async.retn
// define a "cons" function
let cons head tail = head :: tail
// right fold over the list
let initState = retn []
let folder head tail =
retn cons <*> (f head) <*> tail
List.foldBack folder list initState
/// Transform a "list<Async>" into a "Async<list>"
/// and collect the results using apply.
let sequenceAsyncA x = traverseAsyncA id x
/// Map a Result producing function over a list to get a new Result
/// using applicative style
/// ('a -> Result<'b>) -> 'a list -> Result<'b list>
let rec traverseResultA f list =
// define the applicative functions
let (<*>) = Result.apply
let retn = Result.Success
// define a "cons" function
let cons head tail = head :: tail
// right fold over the list
let initState = retn []
let folder head tail =
retn cons <*> (f head) <*> tail
List.foldBack folder list initState
/// Transform a "list<Result>" into a "Result<list>"
/// and collect the results using apply.
let sequenceResultA x = traverseResultA id x
Adding a timer
It will be interesting to see how long the download takes for different scenarios, so let's create a little timer that runs a function a certain number of times and takes the average:
/// Do countN repetitions of the function f and print the time per run
let time countN label f =
let stopwatch = System.Diagnostics.Stopwatch()
// do a full GC at the start but not thereafter
// allow garbage to collect for each iteration
System.GC.Collect()
printfn "======================="
printfn "%s" label
printfn "======================="
let mutable totalMs = 0L
for iteration in [1..countN] do
stopwatch.Restart()
f()
stopwatch.Stop()
printfn "#%2i elapsed:%6ims " iteration stopwatch.ElapsedMilliseconds
totalMs <- totalMs + stopwatch.ElapsedMilliseconds
let avgTimePerRun = totalMs / int64 countN
printfn "%s: Average time per run:%6ims " label avgTimePerRun
Ready to download at last
Let's download some sites for real!
We'll define two lists of sites: a "good" one, where all the sites should be accessible, and a "bad" one, containing invalid sites.
let goodSites = [
"http://google.com"
"http://bbc.co.uk"
"http://fsharp.org"
"http://microsoft.com"
]
let badSites = [
"http://example.com/nopage"
"http://bad.example.com"
"http://verybad.example.com"
"http://veryverybad.example.com"
]
Let's start by running largestPageSizeA 10 times with the good sites list:
let f() =
largestPageSizeA goodSites
|> Async.RunSynchronously
|> showContentSizeResult
time 10 "largestPageSizeA_Good" f
The output is something like this:
[google.com] Started ...
[bbc.co.uk] Started ...
[fsharp.org] Started ...
[microsoft.com] Started ...
[bbc.co.uk] ... finished
[fsharp.org] ... finished
[google.com] ... finished
[microsoft.com] ... finished
SUCCESS: [bbc.co.uk] Content size is 108983
largestPageSizeA_Good: Average time per run: 533ms
We can see immediately that the downloads are happening in parallel -- they have all started before the first one has finished.
Now what about if some of the sites are bad?
let f() =
largestPageSizeA badSites
|> Async.RunSynchronously
|> showContentSizeResult
time 10 "largestPageSizeA_Bad" f
The output is something like this:
[example.com] Started ...
[bad.example.com] Started ...
[verybad.example.com] Started ...
[veryverybad.example.com] Started ...
[verybad.example.com] ... exception
[veryverybad.example.com] ... exception
[example.com] ... exception
[bad.example.com] ... exception
FAILURE: [
"[example.com] "The remote server returned an error: (404) Not Found."";
"[bad.example.com] "The remote name could not be resolved: 'bad.example.com'"";
"[verybad.example.com] "The remote name could not be resolved: 'verybad.example.com'"";
"[veryverybad.example.com] "The remote name could not be resolved: 'veryverybad.example.com'""]
largestPageSizeA_Bad: Average time per run: 2252ms
Again, all the downloads are happening in parallel, and all four failures are returned.
Optimizations
The largestPageSizeA has a series of maps and sequences in it which means that the list is being iterated over three times and the async mapped over twice.
As I said earlier, I prefer clarity over micro-optimizations unless there is proof otherwise, and so this does not bother me.
However, let's look at what you could do if you wanted to.
Here's the original version, with comments removed:
let largestPageSizeA urls =
urls
|> List.map (fun s -> System.Uri(s))
|> List.map getUriContentSize
|> List.sequenceAsyncA
|> Async.map List.sequenceResultA
|> Async.map (Result.map maxContentSize)
The first two List.maps could be combined:
let largestPageSizeA urls =
urls
|> List.map (fun s -> System.Uri(s) |> getUriContentSize)
|> List.sequenceAsyncA
|> Async.map List.sequenceResultA
|> Async.map (Result.map maxContentSize)
The map-sequence can be replaced with a traverse:
let largestPageSizeA urls =
urls
|> List.traverseAsyncA (fun s -> System.Uri(s) |> getUriContentSize)
|> Async.map List.sequenceResultA
|> Async.map (Result.map maxContentSize)
and finally the two Async.maps can be combined too:
let largestPageSizeA urls =
urls
|> List.traverseAsyncA (fun s -> System.Uri(s) |> getUriContentSize)
|> Async.map (List.sequenceResultA >> Result.map maxContentSize)
Personally, I think we've gone too far here. I prefer the original version to this one!
As an aside, one way to get the best of both worlds is to use a "streams" library that automatically merges the maps for you.
In F#, a good one is Nessos Streams. Here is a blog post showing the difference between streams and
the standard seq.
Downloading the monadic way
Let's reimplement the downloading logic using monadic style and see what difference it makes.
First we need a monadic version of the downloader:
let largestPageSizeM urls =
urls
|> List.map (fun s -> System.Uri(s))
|> List.map getUriContentSize
|> List.sequenceAsyncM // <= "M" version
|> Async.map List.sequenceResultM // <= "M" version
|> Async.map (Result.map maxContentSize)
This one uses the monadic sequence functions (I won't show them -- the implementation is as you expect).
Let's run largestPageSizeM 10 times with the good sites list and see if there is any difference from the applicative version:
let f() =
largestPageSizeM goodSites
|> Async.RunSynchronously
|> showContentSizeResult
time 10 "largestPageSizeM_Good" f
The output is something like this:
[google.com] Started ...
[google.com] ... finished
[bbc.co.uk] Started ...
[bbc.co.uk] ... finished
[fsharp.org] Started ...
[fsharp.org] ... finished
[microsoft.com] Started ...
[microsoft.com] ... finished
SUCCESS: [bbc.co.uk] Content size is 108695
largestPageSizeM_Good: Average time per run: 955ms
There is a big difference now -- it is obvious that the downloads are happening in series -- each one starts only when the previous one has finished.
As a result, the average time is 955ms per run, almost twice that of the applicative version.
Now what about if some of the sites are bad? What should we expect? Well, because it's monadic, we should expect that after the first error, the remaining sites are skipped, right? Let's see if that happens!
let f() =
largestPageSizeM badSites
|> Async.RunSynchronously
|> showContentSizeResult
time 10 "largestPageSizeM_Bad" f
The output is something like this:
[example.com] Started ...
[example.com] ... exception
[bad.example.com] Started ...
[bad.example.com] ... exception
[verybad.example.com] Started ...
[verybad.example.com] ... exception
[veryverybad.example.com] Started ...
[veryverybad.example.com] ... exception
FAILURE: ["[example.com] "The remote server returned an error: (404) Not Found.""]
largestPageSizeM_Bad: Average time per run: 2371ms
Well that was unexpected! All of the sites were visited in series, even though the first one had an error. But in that case, why is only the first error returned, rather than all the the errors?
Can you see what went wrong?
Explaining the problem
The reason why the implementation did not work as expected is that the chaining of the Asyncs was independent of the chaining of the Results.
If you step through this in a debugger you can see what is happening:
- The first
Asyncin the list was run, resulting in a failure. Async.bindwas used with the nextAsyncin the list. ButAsync.bindhas no concept of error, so the nextAsyncwas run, producing another failure.- In this way, all the
Asyncs were run, producing a list of failures. - This list of failures was then traversed using
Result.bind. Of course, because of the bind, only the first one was processed and the rest ignored. - The final result was that all the
Asyncs were run but only the first failure was returned.
Treating two worlds as one
The fundamental problem is that we are treating the Async list and Result list as separate things to be traversed over.
But that means that a failed Result has no influence on whether the next Async is run.
What we want to do, then, is tie them together so that a bad result does determine whether the next Async is run.
And in order to do that, we need to treat the Async and the Result as a single type -- let's imaginatively call it AsyncResult.
If they are a single type, then bind looks like this:
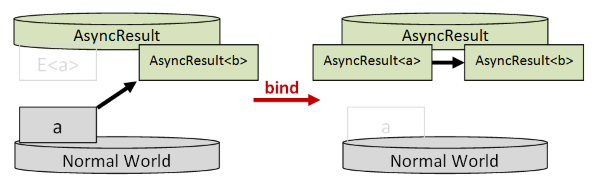
meaning that the previous value will determine the next value.
And also, the "swapping" becomes much simpler:

Defining the AsyncResult type
OK, let's define the AsyncResult type and it's associated map, return, apply and bind functions.
/// type alias (optional)
type AsyncResult<'a> = Async<Result<'a>>
/// functions for AsyncResult
module AsyncResult =
module AsyncResult =
let map f =
f |> Result.map |> Async.map
let retn x =
x |> Result.retn |> Async.retn
let apply fAsyncResult xAsyncResult =
fAsyncResult |> Async.bind (fun fResult ->
xAsyncResult |> Async.map (fun xResult ->
Result.apply fResult xResult))
let bind f xAsyncResult = async {
let! xResult = xAsyncResult
match xResult with
| Success x -> return! f x
| Failure err -> return (Failure err)
}
Notes:
- The type alias is optional. We can use
Async<Result<'a>>directly in the code and it wil work fine. The point is that conceptuallyAsyncResultis a separate type. - The
bindimplementation is new. The continuation functionfis now crossing two worlds, and has the signature'a -> Async<Result<'b>>.- If the inner
Resultis successful, the continuation functionfis evaluated with the result. Thereturn!syntax means that the return value is already lifted. - If the inner
Resultis a failure, we have to lift the failure to an Async.
- If the inner
Defining the traverse and sequence functions
With bind and return in place, we can create the appropriate traverse and sequence functions for AsyncResult:
module List =
/// Map an AsyncResult producing function over a list to get a new AsyncResult
/// using monadic style
/// ('a -> AsyncResult<'b>) -> 'a list -> AsyncResult<'b list>
let rec traverseAsyncResultM f list =
// define the monadic functions
let (>>=) x f = AsyncResult.bind f x
let retn = AsyncResult.retn
// define a "cons" function
let cons head tail = head :: tail
// right fold over the list
let initState = retn []
let folder head tail =
f head >>= (fun h ->
tail >>= (fun t ->
retn (cons h t) ))
List.foldBack folder list initState
/// Transform a "list<AsyncResult>" into a "AsyncResult<list>"
/// and collect the results using bind.
let sequenceAsyncResultM x = traverseAsyncResultM id x
Defining and testing the downloading functions
Finally, the largestPageSize function is simpler now, with only one sequence needed.
let largestPageSizeM_AR urls =
urls
|> List.map (fun s -> System.Uri(s) |> getUriContentSize)
|> List.sequenceAsyncResultM
|> AsyncResult.map maxContentSize
Let's run largestPageSizeM_AR 10 times with the good sites list and see if there is any difference from the applicative version:
let f() =
largestPageSizeM_AR goodSites
|> Async.RunSynchronously
|> showContentSizeResult
time 10 "largestPageSizeM_AR_Good" f
The output is something like this:
[google.com] Started ...
[google.com] ... finished
[bbc.co.uk] Started ...
[bbc.co.uk] ... finished
[fsharp.org] Started ...
[fsharp.org] ... finished
[microsoft.com] Started ...
[microsoft.com] ... finished
SUCCESS: [bbc.co.uk] Content size is 108510
largestPageSizeM_AR_Good: Average time per run: 1026ms
Again, the downloads are happening in series. And again, the time per run is almost twice that of the applicative version.
And now the moment we've been waiting for! Will it skip the downloading after the first bad site?
let f() =
largestPageSizeM_AR badSites
|> Async.RunSynchronously
|> showContentSizeResult
time 10 "largestPageSizeM_AR_Bad" f
The output is something like this:
[example.com] Started ...
[example.com] ... exception
FAILURE: ["[example.com] "The remote server returned an error: (404) Not Found.""]
largestPageSizeM_AR_Bad: Average time per run: 117ms
Success! The error from the first bad site prevented the rest of the downloads, and the short run time is proof of that.
Summary
In this post, we worked through a small practical example. I hope that this example demonstrated that
map, apply, bind, traverse, and sequence are not just academic abstractions but essential tools in your toolbelt.
In the next post we'll working through another practical example, but this time we will end up creating our own elevated world. See you then!