How to design and code a complete program
"I think I understand functional programming at the micro level, and I have written toy programs, but how do I actually go about writing a complete application, with real data, real error handling, and so on?"
This is a very common question, so I thought that in this series of posts I'd describe a recipe for doing exactly this, covering design, validation, error handling, persistence, dependency management, code organization, and so on.
Some comments and caveats first:
- I'll focus on just a single use case rather than a whole application. I hope that it will be obvious how to extend the code as needed.
- This will deliberately be a very simple data-flow oriented recipe with no special tricks or advanced techniques. But if you are just getting started, I think it is useful to have some straightforward steps you can follow to get a predictable result. I don't claim that this is the one true way of doing this. Different scenarios will need different recipes, and of course, as you get more expert, you may find this recipe too simplistic and limited.
- To help ease the transition from object-oriented design, I will try to use familiar concepts such as "patterns", "services", "dependency injection", and so on, and explain how they map to functional concepts.
- This recipe is also deliberately somewhat imperative, that is, it uses an explicit step-by-step workflow. I hope this approach will ease the transition from OO to FP.
- To keep things simple (and usable from a simple F# script), I'll mock the entire infrastructure and avoid the UI directly.
Overview
Here's an overview of what I plan to cover in this series:
- Converting a use-case into a function. In this first post, we'll examine a simple use case and see how it might be implemented using a functional approach.
- Connecting smaller functions together. In the next post, we'll discuss a simple metaphor for combining smaller functions into bigger functions.
- Type driven design and failure types. In the third post, we'll build the types needed for the use case, and discuss the use of special error types for the failure path.
- Configuration and dependency management. In this post, we'll talk about how to wire up all the functions.
- Validation. In this post, we'll discuss various ways of implementing validation, and converting from the unsafe outside world to the warm fuzzy world of type safety.
- Infrastructure. In this post, we'll discuss various infrastructure components, such as logging, working with external code, and so on.
- The domain layer. In this post, we'll discuss how domain driven design works in a functional environment.
- The presentation layer. In this post, we'll discuss how to convey results and errors back to the UI.
- Dealing with changing requirements. In this post, we'll discuss how to deal with changing requirements and the effect this has on the code.
Getting started
Let's pick a very simple use case, namely updating some customer information via a web service.
So here are the basic requirements:
- A user submits some data (userid, name and email).
- We check to see that the name and email are valid.
- The appropriate user record in a database is updated with the new name and email.
- If the email has changed, send a verification email to that address.
- Display the result of the operation to the user.
This is a typical data centric use case. There is some sort of request that triggers the use case, and then the request data "flows" through the system, being processed by each step in turn. This kind of scenario is common in enterprise software, which is why I am using it as an example.
Here's a diagram of the various components:
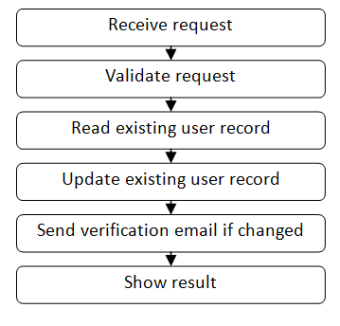
But this describes the "happy path" only. Reality is never so simple! What happens if the userid is not found in the database, or the email address is not valid, or the database has an error?
Let's update the diagram to show all the things that could go wrong.
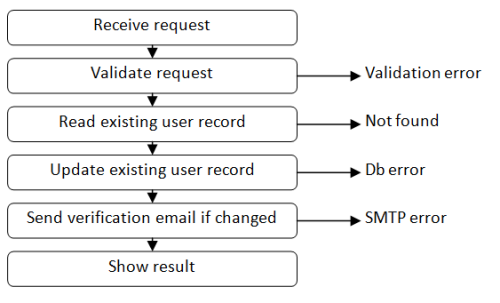
At each step in the use case, various things could cause errors, as shown. Explaining how to handle these errors in an elegant way will be one of the goals of this series.
Thinking functionally
So now that we understand the steps in the use case, how do we design a solution using a functional approach?
First of all, we have to address a mismatch between the original use case and functional thinking.
In the use case, we typically think of a request/response model. The request is sent, and the response comes back. If something goes wrong, the flow is short-circuited and response is returned "early".
Here's a diagram showing what I mean, based on a simplified version of the use case:
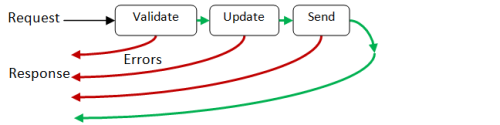
But in the functional model, a function is a black box with an input and an output, like this:

How can we adapt the use case to fit this model?
Forward flow only
First, you must recognize that functional data flow is forward only. You cannot do a U-turn or return early.
In our case, that means that all the errors must be sent forward to the end, as an alternative path to the happy path.
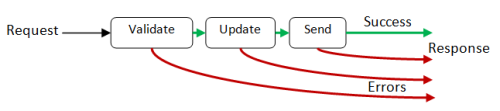
Once we have done that, we can convert the whole flow into a single "black box" function like this:

But of course, if you look inside the big function, it is made up of ("composed from" in functional-speak) smaller functions, one for each step, joined in a pipeline.
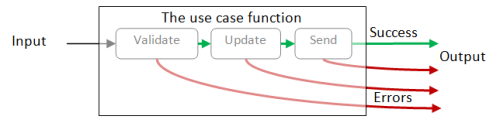
Error handling
In that last diagram, there is one success output and three error outputs. This is a problem, as functions can have only one output, not four!
How can we handle this?
The answer is to use a union type, with one case to represent each of the different possible outputs. And then the function as a whole would indeed only have a single output.
Here's an example of a possible type definition for the output:
type UseCaseResult =
| Success
| ValidationError
| UpdateError
| SmtpError
And here's the diagram reworked to show a single output with four different cases embedded in it:

Simplifying the error handling
This does solve the problem, but having one error case for each step in the flow is brittle and not very reusable. Can we do better?
Yes! All we really need is two cases. One for the happy path, and one for all other error paths, like this:
type UseCaseResult =
| Success
| Failure

This type is very generic and will work with any workflow! In fact, you'll soon see that we can create a nice library of useful functions that will work with this type, and which can be reused for all sorts of scenarios.
One more thing though -- as it stands there is no data in the result at all, just a success/failure status. We need to tweak it a bit so that it can contain an actual success or failure object. We will specify the success type and failure type using generics (a.k.a. type parameters).
Here's the final, completely generic and reusable version:
type Result<'TSuccess,'TFailure> =
| Success of 'TSuccess
| Failure of 'TFailure
In fact, there is already a type almost exactly like this defined in the F# library. It's called Choice. For clarity though, I will continue to use the Result type defined above for this and the next post. When we come to some more serious coding, we'll revisit this.
So, now, showing the individual steps again, we can see that we will have to combine the errors from each step onto to a single "failure" path.

How to do this will be the topic of the next post.
Summary and guidelines
So far then, we have the following guidelines for the recipe:
Guidelines
- Each use case will be equivalent to a single function
- The use case function will return a union type with two cases:
SuccessandFailure. - The use case function will be built from a series of smaller functions, each representing one step in a data flow.
- The errors from each step will be combined into a single error path.